python
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import requests
from bs4 import BeautifulSoup
import os
url = ['http://www.daimg.com/photo/list_4_{}.html'.format(str(i)) for i in range(1, 11)]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4208.400'
}
def get_meimei(url):
web_data = requests.get(url=url, headers=headers)
soup = BeautifulSoup(web_data.text, "html.parser")
img_src = soup.find_all('img')
luoyubao = []
for luo in img_src:
luoyubao.append(luo.get('src'))
for img in luoyubao:
with open("D:\\imgdownload\\" + os.path.basename(img), 'wb') as f:
try:
f.write(requests.get(img).content)
except:
print("sb")
print(os.path.basename(img) + "保存成功");
for titles in url:
get_meimei(titles)
|
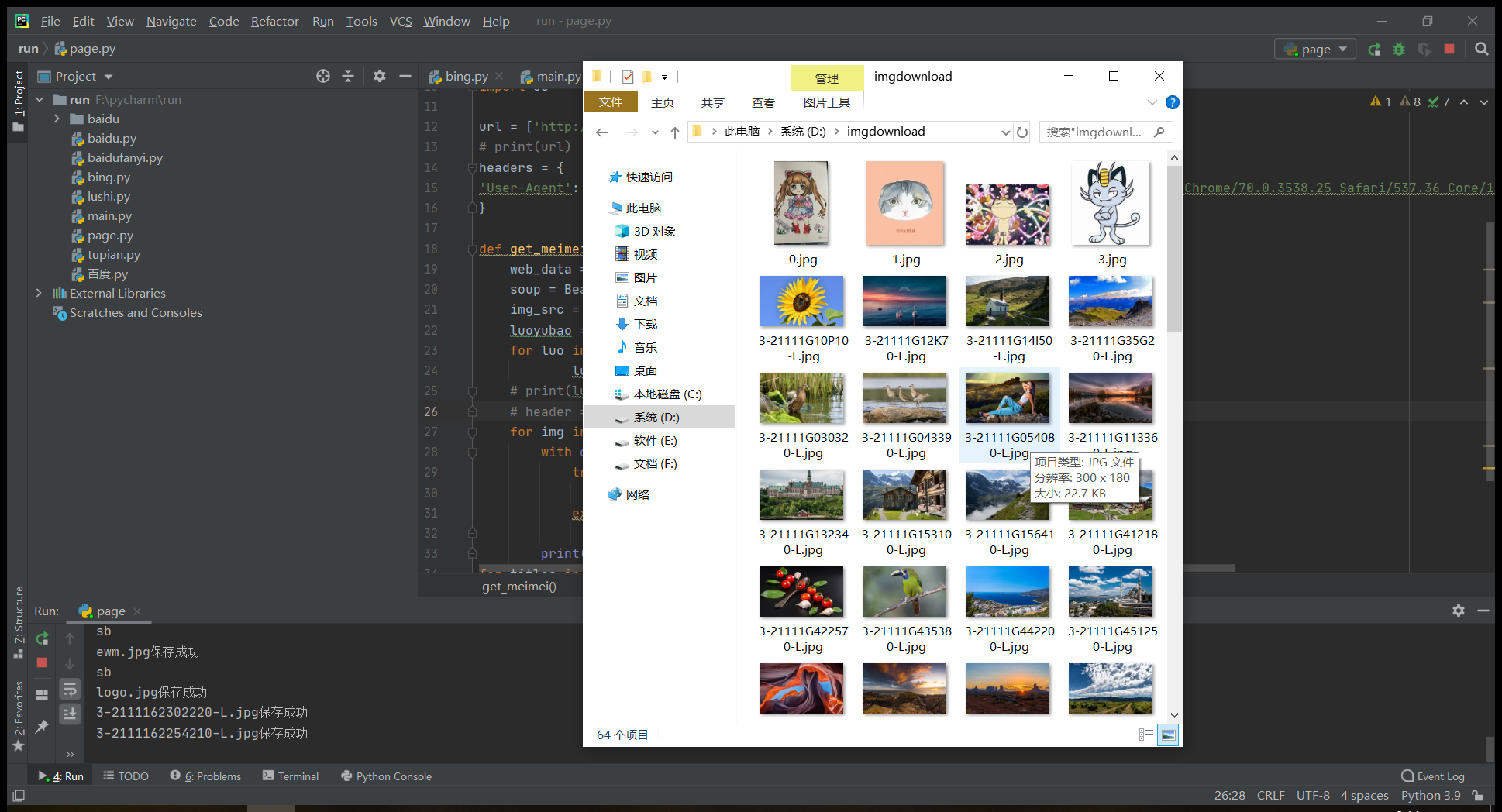
图片: